

数据处理与可视化
pd.read_excel('各级各类学历教育招生人数汇总表.xlsx', header=1) 是使用 pandas 库读取 Excel 文件的常见操作。这个命令会读取文件各级各类学历教育招生人数汇总表.xlsx,并将第1行(即第二行)作为列名。此时输出df的数据如图1所示。
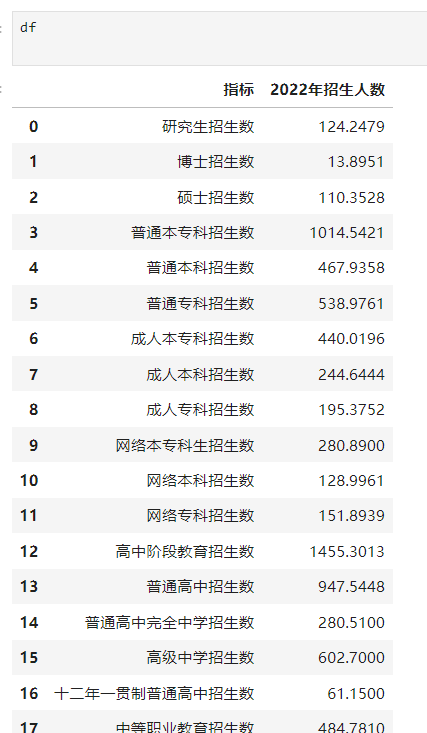
图1 df中部分数据结果
在Pandas库中,df.iloc 是一个非常常用的属性,用于基于位置的索引,可以对DataFrame的行和列进行选择和操作。iloc 是 “integer location” 的缩写,意味着它使用整数索引,即使这些整数不是 DataFrame 索引标签的一部分。df.iloc[start:stop:step] 是一个基于整数索引的切片操作,其中:start是起始索引,包含在内;stop 是结束索引,不包含在内;step 是步长,表示每隔多少个元素取一个。对于 df.iloc[0:12:3]:start 是 0,表示从索引 0 开始。stop 是 12,表示选取到索引 12 之前(即索引 11)。step 是 3,表示每隔 3 个元素取一个。返回 DataFrame 中从索引 0 开始,每隔 3 个索引取一个,直到索引12之前(不包括索引 12)的行。访问的是第0行、第3行、第6行和第9行的数据。在Python中,索引是从0开始的,所以索引0对应第一行,索引3对应第四行,索引6对应第七行,索引9对应第十行,所以,df.iloc[0:12:3] 访问的是第一行、第四行、第七行和第十行的数据。如图2所示。
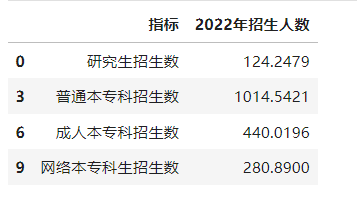
图2 df1获取的数据
df1.sort_values 是 pandas 库中的一个方法,用于对 DataFrame 中的数据进行排序。具体来说,sort_values 方法可以根据指定的列或多个列对 DataFrame 中的行进行排序。by:指定用于排序的列名或列名列表。可以是一个字符串(单列)或一个列表(多列)。ascending:指定排序顺序。True 表示升序(默认),False 表示降序。上述代码按招生人数大小降序排列,排序后的结果如图63所示。list(data1['2022年招生人数'])这行代码的作用是将data1 DataFrame中'2022年招生人数' 列的数据转换为一个 Python 列表。转换后的结果存储到data中,data的结果如图4所示。list(data1['指标']) 这行代码的作用是将 data1 DataFrame 中 '指标'列的数据转换为一个 Python 列表。 转换后的结果存储到la'bel中,la'bel的结果如图5所示,以便用作饼图的标签。
饼图的标签是用于标识饼图中各个部分的文字说明。这些标签通常对应于数据中的分类或类别名称,帮助读者理解每个部分代表的意义。
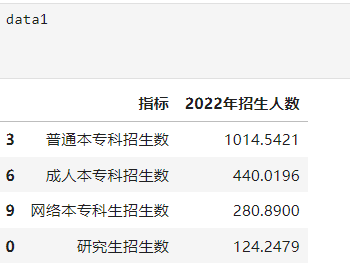
图3 按招生人数大小降序排列
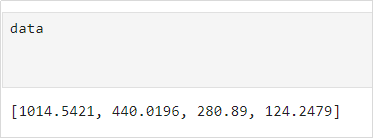
图4 数据转换为Python 列表

图5 '指标'列的数据转换为一个 Python 列表



